The post How to Prevent Scraping of a Website: Keeping Your Content Safe appeared first on Tech Today Info.
]]>Some legitimate uses of data scraping involve:
· Search engines crawl your site and analyze your content to help in ranking purposes.
· Market research companies that scrape data from social media sites for sentiment analysis.
· Price comparison sites deploy bots to help auto-fetch product descriptions and prices to be used by allied seller websites.
The tools (software) used are programmed to scrutinize databases to extract useful information that the scrapper can use. Various bots can be used, and many of them are often fully customized to:
· Extract and change content
· Identify distinctive HTML site configurations
· Store the scraped files
· Mine information from APIs
You’ll need to be aware of two facts if you want to prevent the scrapping of a website: It’s extremely hard to prevent scrapers from scraping data from websites since scrappers seem to be getting more creative by the day. Creating too many web scraping barriers on your content could keep out useful bots like Google’s web scrapping bots used for web ranking.
How do you go about it?
How to prevent scraping of a website
The following is a list of some general strategies that you could use to prevent scraping on websites.

1. You could begin by limiting access if you notice any unusual activities
If you want to prevent website scraping, you could start by monitoring your website’s logs and traffic patterns. Suppose you see any unusual activity pointing towards automated access, like similar actions originating from one IP address. In that case, you could go ahead and block them or limit their access.
You could do:
Rate limiting
You could go ahead and allow your website users to perform a limited amount of actions over a specified period. This could include excessive searches per second per IP address and users that look at an unusual number of pages per IP address.
You could use captchas for any subsequent requests or even limit access if you notice that actions are being completed faster than real users would- doing this will help make scraping bots ineffective.
Use various indicators to monitor scrape bots’ activities.
Blanket-blocking IP addresses could hurt your traffic. However, if you use other indicators to weed out malicious IP addresses and scrapers, you can make it easier for you to maintain your traffic while simultaneously blocking scraping bots.
You could try to identify scrapers by:
· Identify how quickly users fill out forms on your website and where they click on the buttons.
· You could also use JavaScript to gather information like screen size, installed fonts, time zone, etc., to help you identify users.
· You could also use user-agent HTTP headers and order to identify users or scrapers that may be looking to scrape information from your website.
How can you use this information? You could try and identify IP addresses that send out multiple requests in a short period which come in a preset frequency and click on buttons at regular intervals and in a similar way.
Comparing such users through their screen size and fonts could provide you with a list of potential scrapers that you could temporarily block. You could also use these characteristics to identify potential scrapers who share similar characteristics but are using different IP addresses.
2. Using registration and login
You could also require users to create an account before they can view your content. However, one problem observed when using this strategy is that it can turn out to be a hindrance for both scrapers and users.
Requiring your website users to create an account makes it easier to determine accounts that may be scraping data from your website using the indicators mentioned above. It helps you identify specific scraper identities instead of only getting their IP addresses.
You could perfect this strategy by having your users use one email per account, where a link that users must click to activate the account is sent to their email. For extra security, you could have your users solve a simple capture during the registration process.
However, while this may keep your content safe, you could be driving away users who would rather not fill out the registration and search engine bots that may want to use your content to rank your account. You could compromise by providing users with an excerpt of your content to entice them into creating an account.
3. Block access from scrap service and web hosting IP addresses
Some scrapers are run from web hosting services or VPSes. You could avoid requests that originate from cloud hosting services by limiting them or using captchas. You could also go ahead and block requests from IP addresses that originate from similar devices as those that come from scraping services.
You could also block requests from VPN providers since some scrapers may use VPN to prevent you from detecting their multiple requests. However, be aware that you may be blocking a huge number of real users by doing this.
4. If you do block scrapers, ensure that the errors are nondescript
If you choose to block IP addresses that may be making too many requests, ensure that you do not inform them of the same since they may use the information to improve their scrapers. You could avoid displaying messages like:
· Error! User Agent’s Header not available!
· Too many IP addresses from this IP address; try again later.
Instead, you could go for a friendly message that doesn’t inform the scraper you are onto them but is polite to your users. You could go for something like ‘Sorry, this doesn’t usually happen. If the problem persists, visit [email protected].’ You could then go ahead and verify the user with a captcha.
5. Using captchas
If you suspect that scraper may be using your website, then the best step to take is using a simple captcha. While captcha solutions effectively differentiate humans from computers, they can be irritating to users who want to read your website’s content.
You could use captchas if you suspect scraper activity; however, to be on the safe side, it would be good to ensure that the capture is relatively simple and that it isn’t the first thing a user sees after accessing your website.
Note that:
· Please use Google’s reCaptcha instead of creating your captcha. Google’s reCaptcha is simple enough not to irritate your users but too complex to be solved by scraper bots.
· If you decide to create your recapture, ensure that you don’t include its solution in your page’s HTML markup. The scraper will find and use the solution to solve your capture. Instead, use Google’s recapture, and you won’t have to experience this problem.
· There are groups that help solve captchas in bulk, making it easier for scrapers to access websites. While this may undermine the use of captchas, it becomes a problem where the information being scraped is highly valuable.
6. You could serve your content in image form.
You could render your website’s text content into an image server-side and have it displayed as an image. Doing this will prevent simple scrappers from accessing your content. However, this could affect search engines, screen readers, performance, and so much more. It could also be illegal in some places, i.e., the Americans with Disabilities Act.
7. Avoid exposing your entire data set.
Avoid exposing your entire data set if you can. You could design it so that users and scrapers have to search for individual pieces of information on the onsite search using phrases. This could be time-consuming and inefficient. Ensure that you don’t have a list of the articles and their URLs onsite.
This strategy is effective when:
· The scraper wants a particular set of information
· Your article’s URLs don’t follow a specific pattern that scraping bots can figure out.
· If your articles don’t have links that connect them
· There aren’t any words like and that can be used to like most of the articles together
· Your content doesn’t require search engine bots to crawl your website and rank better
8. Other steps you may need to take to protect your content
You take steps to ensure that you change your HTML often to prevent scrapers from gleaning off identifiable parts that they could use to access content from your website. Ensure that you change the classes of elements and ids to make it harder for scrapers to get any desired content.
You could also change your website’s HTML based on the user’s location. Doing this helps break scrapers that are delivered to users. For instance, if developers create mobile apps that scrape data from websites, they may work initially but fail to work as soon as they are distributed.
You could also create fake and invincible honeypot data that only scrappers can link to. You could then block out the scraper’s bots for 24 hours if they click on the link. This and various other honeypot schemes could help deter scrapper bots and simultaneously keep your data safe.
Conclusion
Preventing scrapper activity from your website is hard, and most of the time, it isn’t 100 % foolproof. However, if you want to keep your data safe, you have no option other than to try as hard as possible to deter any scrap bot activity. You could use different creative ways to keep your data safe; however, the most important thing is to ensure that your methods don’t interfere with your legitimate users’ activities.
The post How to Prevent Scraping of a Website: Keeping Your Content Safe appeared first on Tech Today Info.
]]>The post How Web Scraping Can Help You appeared first on Tech Today Info.
]]>Those who deal with specific data would find the process more complex. Especially data that has to be continuously updated or one that is not so common, such as prices, rates, time, listings, and so on. Searching for such data can take time and consume more resources, not to mention the fact that you may post inaccurate or outdated data. What can you do? How can you improve your search method? By using a web scraper.
A web scraper scours a web page for specific data or information. The scraper goes below the surface, only picking things it has been programmed to do. Say, for example, you program a web scraper to search for data related to “cartoons for kids” on a cinema website, it would give you only results that have to do with cartoons for kids and nothing more. Smart, right? But that is not all it can do.
We live in a world where information is constantly being updated, so something correct a few hours ago may be wrong this minute. This is common in prices and rates so anybody dealing in such business would need to be constantly informed to always he correct. But finding information is not always easy, as that would require sifting through large, unnecessary data. In such a case, a web scraper can come in handy.
If you are still wondering how web scrapers can help you, today at Zenscrape, we have compiled a list of possible ways you can apply web scraping.
First, you need to understand the advantage web scraping has over manual inquiry or search.
1. Faster
Web scraping takes less time to find more data compared to more traditional ways of doing it.
2. Accurate
With web scraping, you can be sure of finding data that is accurate since it is extracted from the site, hence no chance of having errors.
3. Large-volume
Web scraping can also get used to gather large volumes of data with ease. This gives it an edge over other methods.
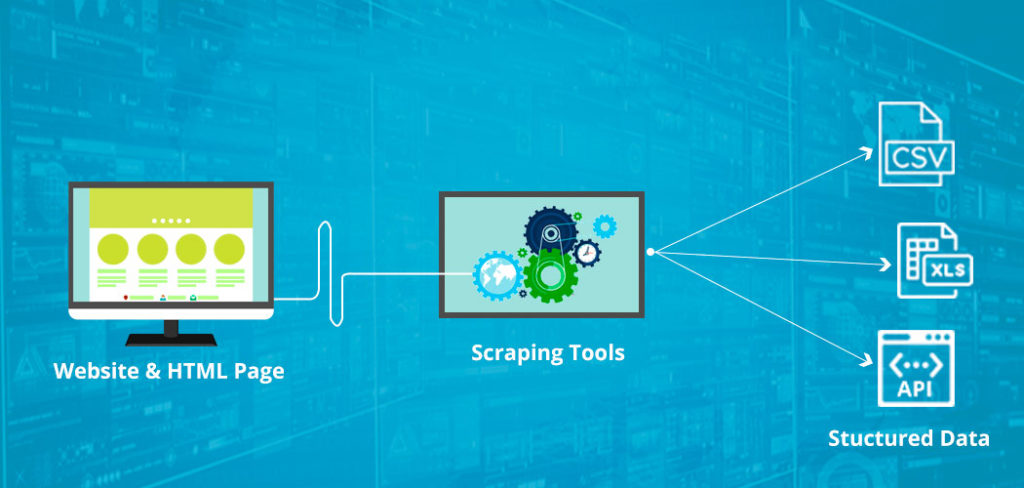
Here are some of the following ways you can apply web scraping
1. Academic Research
Believe it or not, web scraping can save you lots of time in your academic research work. The work of research requires that you gather as much information on specific data. This can be tedious when you do that on the internet as you are bound to come across so many unnecessary information. But having a web scraper can help you save time and even so it better. Simply come up with relevant sites and set up the parameters to include tags that could be useful to you, and let the scraper do the work. You can continue to redefine the parameters to make the search more and more specific.
2. Job listings
If you need to know available vacancies in a particular company, department or a specific position, then let your web scraper do the job for you by visiting various sites to pull information related to the job you want for you to use an act upon. This is very great if you run a site that advertises jobs.
3. Booking sites
Websites that deal with booking, whether for travel or hotels would find web scraping very useful for them as it helps them save time. These types of sites have to display prices in real-time since they are always subject to change. Looking for the latest prices manually and updating it could cost you serious time. Allow your web scraper to go to work and give you the latest information as it constantly scrapes relevant sites.
4. Directory Sites
Sites that act as a directory, providing the contact of businesses, firms, schools, and even people need a great ton of information related to the business or people they list, including addresses, phone numbers, emails, and so on. Getting such data is not so easy and a lot of time has to be vested into it. But you can skip through all that with a web scraper.
5. Competitor’s Activities
Businesses into trade or e-commerce can use web scraping to track and monitor their competitor’s activities including prices, products, and reviews. This allows them to restrategize or follow the trend of their competitors.
Web scraping is useful to everybody and can help make work easier and better. Gone are the days of getting irrelevant or inaccurate data. With a web scraper, you can be sure of getting the exact data you need for your personal or commercial project.
The post How Web Scraping Can Help You appeared first on Tech Today Info.
]]>